Thinking in Graphs
neo4j graph theory graph database
Graphs Theory History
Graph theory was invented by Lenohard Euler.
Back in 1736, in Königsberg, Prussia, Euler was thinking about is it possible to walk through the city of Königsberg (which is divided by 4 regions) by crossing all 7 bridges of the city only once.
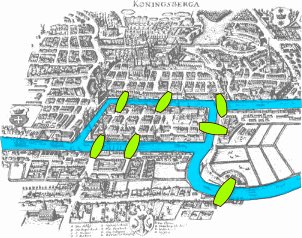
He started solving the problem by focusing on each region of the city, but later realized that he should be focusing on the relationships between the regions.
In abstract terms, he represented the city regions as an abstract node or vertex and the bridges as relationships or edges. These elements formed a graph.
Elements of A Graph
There are 2 elements in a graph:
- Nodes
- Relationships
Nodes
Nodes represents an entity in the graph. For example, nodes can represent a person, location, item, etc. A node can contain properties.
Relationships
Relationships represent a connection between two nodes. For example, a relationship can represent friendship between two persons, ownership of an item, a connection between two locations, a connection between a person and a location, etc. A relationship can contain properties. It can be directed or undirected. It can also be weighted.
Graphs are everywhere
Graphs problems are everywhere.
One example is building a recommendation for a retailer, By using graphs you can easily analyze historical transactions and build a recommendation system based on the historical data by tracing the possibility of similar people who has bought the same product that another person is about buy in real-time.
Another example is investigative journalism. International Consortium of Investigative Journalists (ICIJ) used graphs to analyze the Panama Papers with purpose to identify possible corruption based upon the relationships between people, companies, and most importantly financial institutions.

Other use case / industry examples of graph problems can be explored on neo4j’s graph gist.
Graphs in Neo4j
Nodes
- Nodes are categorized into labels. A node can have one or more labels.
- Nodes can have infinite number of properties.
Relationships
- Relationships must be directed.
- Relationships must be given a type.
- Relationships can have infinite number of properties.
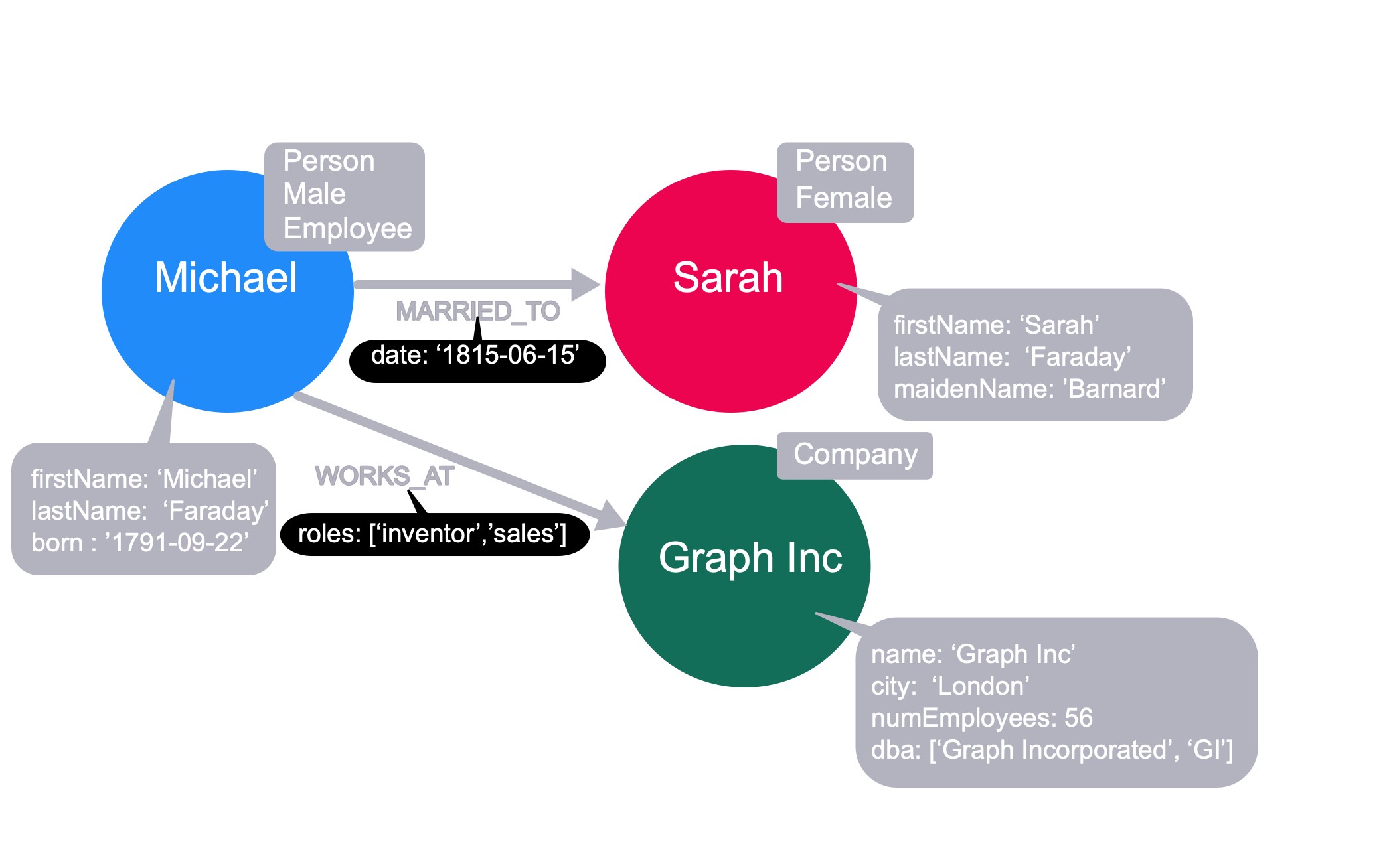
What is Neo4j
Neo4j is a native graph database, meaning that everything from the storage of the data to the query language have been designed specifically with traversal in mind.
The power of Neo4j as a native graph database is the concept of index-free adjacency. This means that everytime a database transaction is written/committed to the database, the relationship between nodes is stored in a graph as pointers. This means that every node are aware of it’s pointers (relationships), scanning (database reading) is done by traversing along the pointers, resulting in faster graph traversal and fewer index lookups. However, this also means that writing to a graph database is slower compared to RDBMS because the relationships in Neo4j is stored directly in the database whereas in an RDMBS, the relationships are not stored in the database and only accessed during reads.
RDBMS vs Neo4j
RDBMS
How you store a graph in a RDBMS looks as follows:
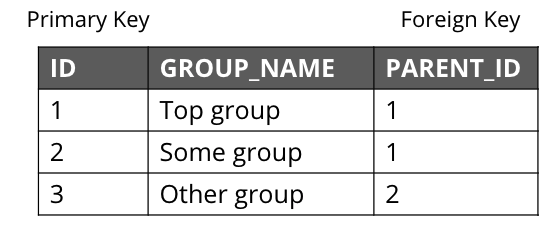
If you want to find the third-degree parent of the group with ID 3, your SQL query will look like:
SELECT PARENT_ID
FROM GROUPS
WHERE ID = (SELECT PARENT_ID
FROM GROUPS
WHERE ID = (SELECT PARENT_ID
FROM GROUPS
WHERE ID = 3))When broken down, the query is composed of the following steps:
- Locate the innermost clause.
- Build the query plan for the subclause.
- Execute the query plan for the subclause.
- Locate the next innermost clause.
- Repeat Steps 2-4.
Resulting in:
- 3 planning cycles
- 3 index lookups
- 3 DB reads
Neo4j
With index-free adjacency in Neo4j, the same graph will look like:

The nodes and relationships are stored as:

The cypher (Neo4j’s query language) is:
MATCH (n) <-- (:Group) <-- (:Group) <-- (:Group {id: 3})
RETURN n.idIn Neo4j, the query will be executed as:

- Plan the query based upon the anchor specified.
- Use an index to retrieve the anchor node.
- Follow pointers to retrieve the desired result node.
The benefits of index-free adjacency in Neo4j compared with RDBMS are:
- Fewer index lookups.
- No table scans.
- Reduced duplication of data.
Neo4j vs NoSQL
We’ve seen how Neo4j compares to RDBMS. But what about NoSQL?
The flexibility of NoSQL offers similar power to store unlimited entity properties as Neo4j. However, data in NoSQL are graphs there are shortcomings.
Key-value store NoSQL
In order to store graph data in key-value store NoSQL, you’re data will look like this:
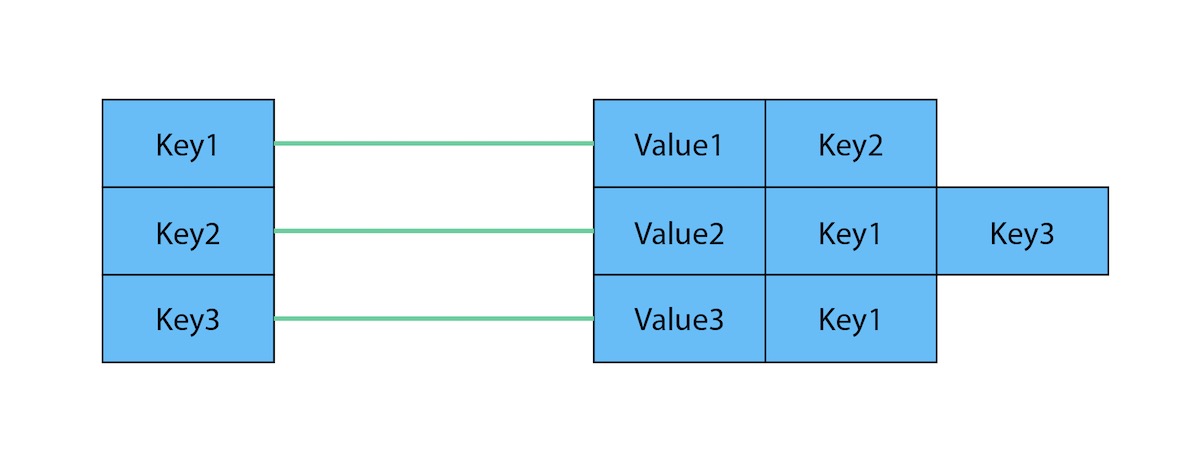
When converted to a graph, the data will look like this:
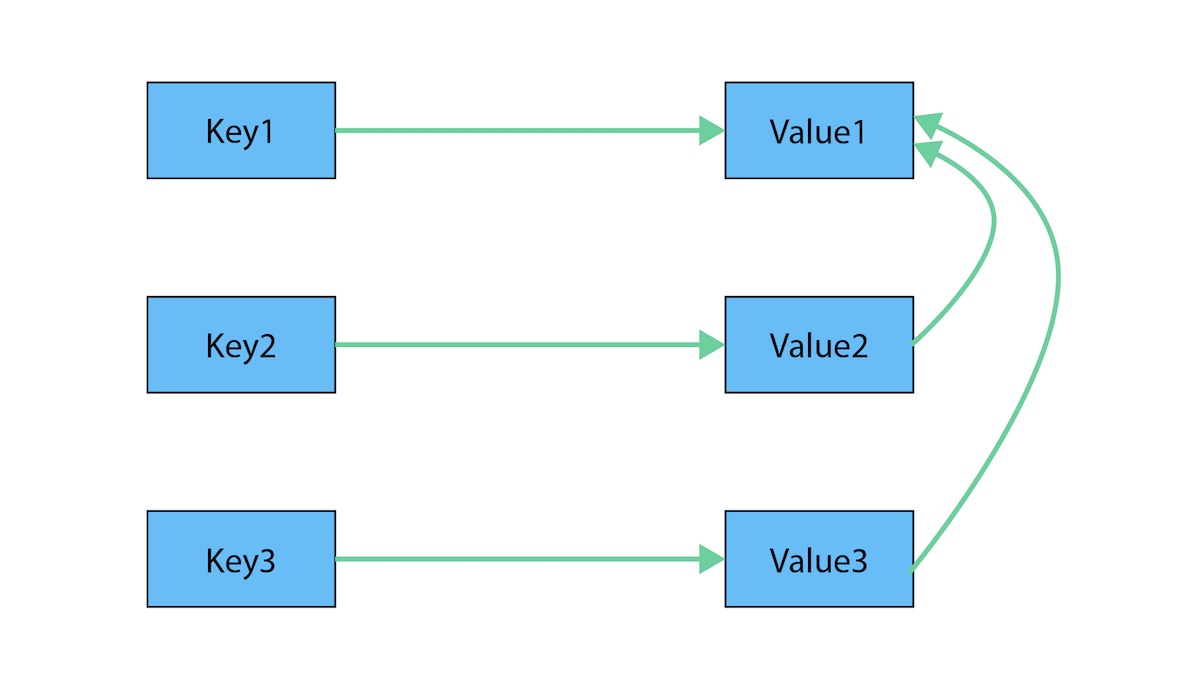
By looking at how the data is stored, converting the data into graph comes with several issues which are as follows:
- The data is interconnected
- The data is redundant
Document store NoSQL
Graph data in a document store NoSQL is stored like this:
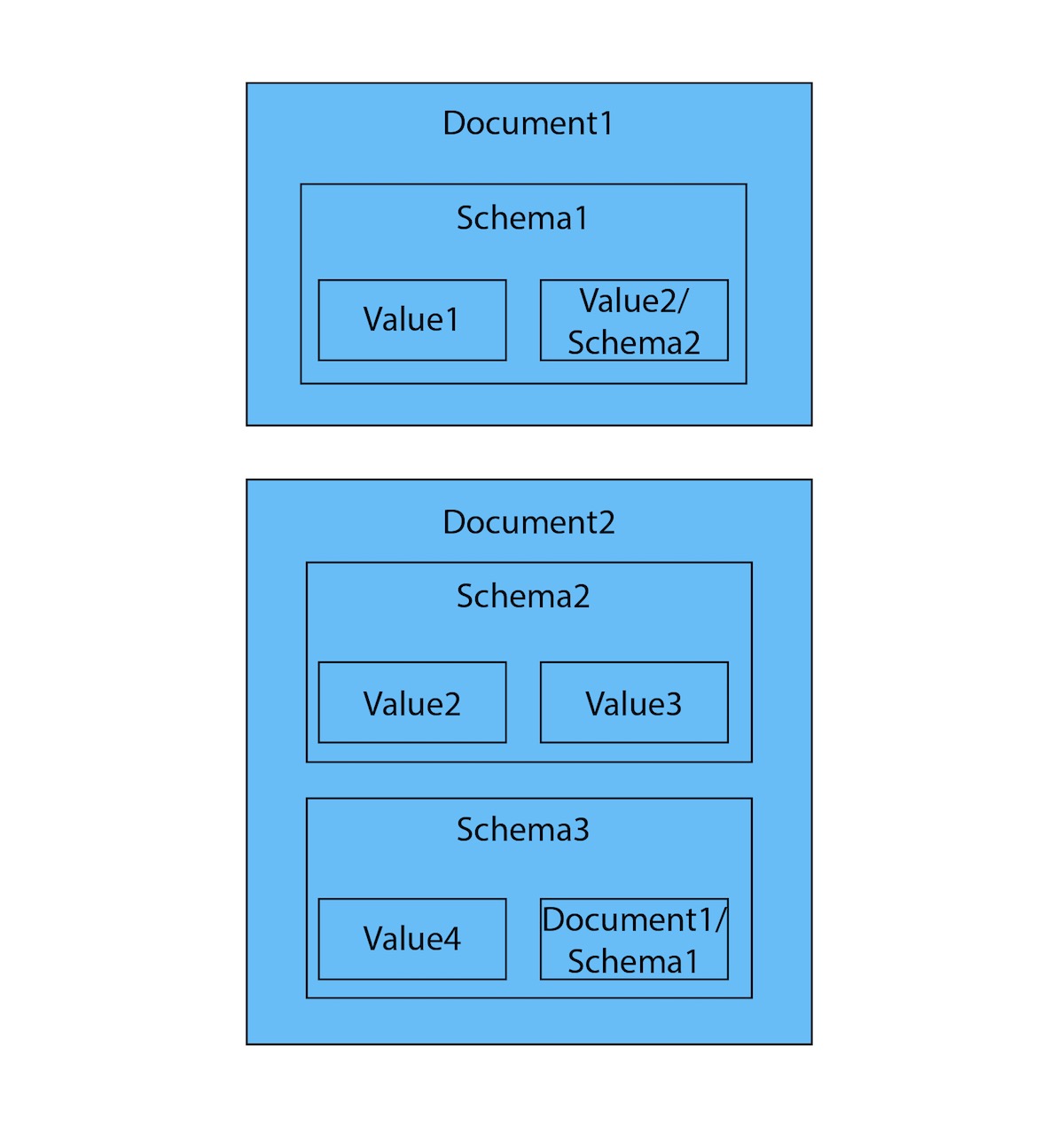
The graph representation of the same data is like this:
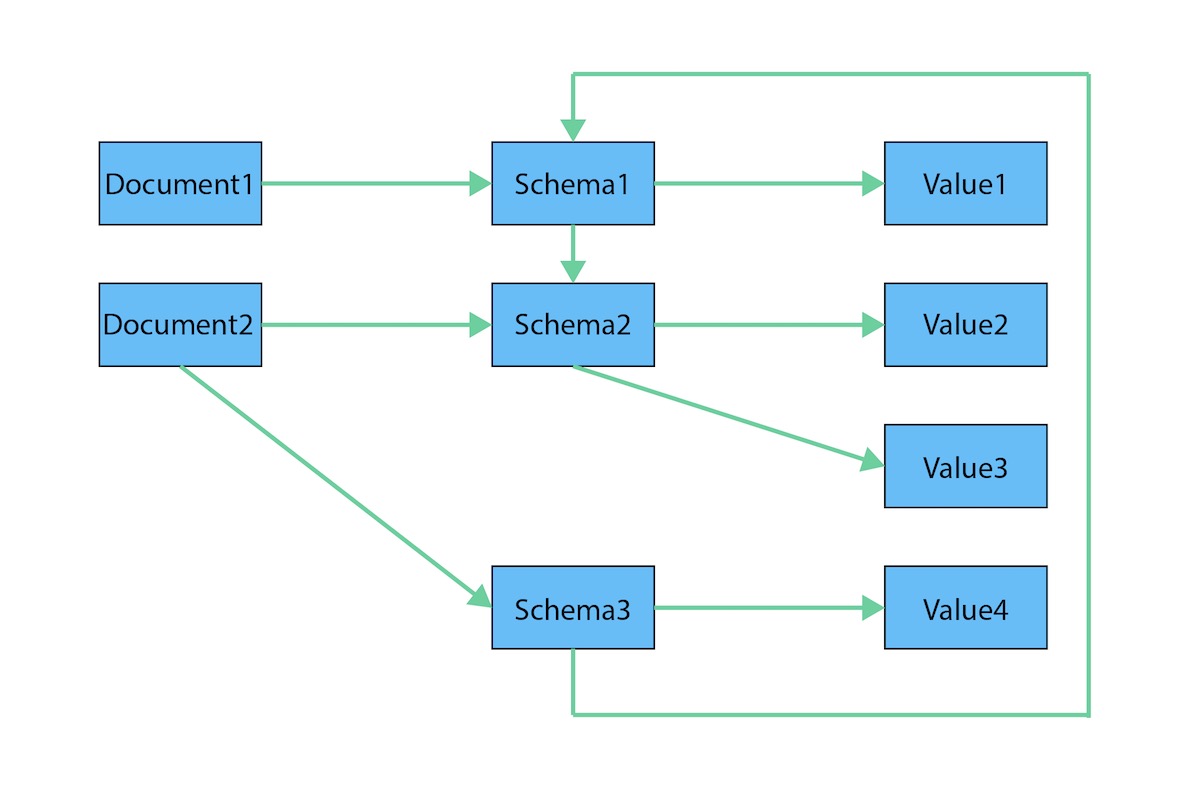
Whilst the data in a document store NoSQL is representing a tree, when trying to store a graph in the document store, the data redundancy also occurs. Resulting in more storage usage and interconnecivity issues.
When you need all the data to be connected, Neo4j is a better choice.