Introduction to graph data modeling using Neo4j
neo4j graph database cypher data modeling graph data modeling
What is Graph Data Modeling
Why Data Modeling is Important?
As explained in “Thinking in Graphs”, graphs are everywhere. Even though it can be found everywhere, finding answers to your questions is not going to be an easy task if you don’t model it properly. Besides of that, your queries in Neo4j might also be slow when your graph is not modeled properly.
Components of A Neo4j Graph
- Nodes
- Labels
- Properties
- Relationships
Data modeling process
Here are the steps to create a graph data model:
- Understand the domain and define specific use cases (questions) for the application.
- Develop the initial graph data model: a. Model the nodes (entities). b. Model the relationships between nodes.
- Test the use cases against the initial data model.
- Create the graph (instance model) with test data using Cypher.
- Test the use cases, including performance against the graph.
- Refactor (improve) the graph data model due to a change in the key use cases or for performance reasons.
- Implement the refactoring on the graph and retest using Cypher.
Things to note, Neo4j has a flexible schema, allowing it to be easily modified to fit the use case you’re handling. Since data modeling is an iterative process, refactoring becomes a common thing in graph data modeling and Neo4j’s flexible schema allows the process to be done easily.
The Domain
Steps to understand the domain of your application
- Identify the stakeholders and developers of the application.
- With the stakeholders and developers:
- Describe the application in detail.
- Identify the users of the application (people, systems).
- Agree upon the use cases for the application.
- Rank the importance of the use cases.
Example (Movie Domain)
Remember the movie dataset in the previous writing?

The domain of this dataset includes movies, people who acted or directed movies, and users who rated movies. What makes this domain interesting are the connections or relationships between nodes in the graph.
Here are some questions to be used for the movie dataset use case:
- What people acted in a movie?
- What person directed a movie?
- What movies did a person act in?
- How many users rated a movie?
- Who was the youngest person to act in a movie?
- What role did a person play in a movie?
- What is the highest rated movie in a particular year according to imDB?
- What drama movies did an actor act in?
- What users gave a movie a rating of 5?
Type of Models
There are 2 types of models for graph data modeling in Neo4j.
- Data Model
- Instance Model
Data Model
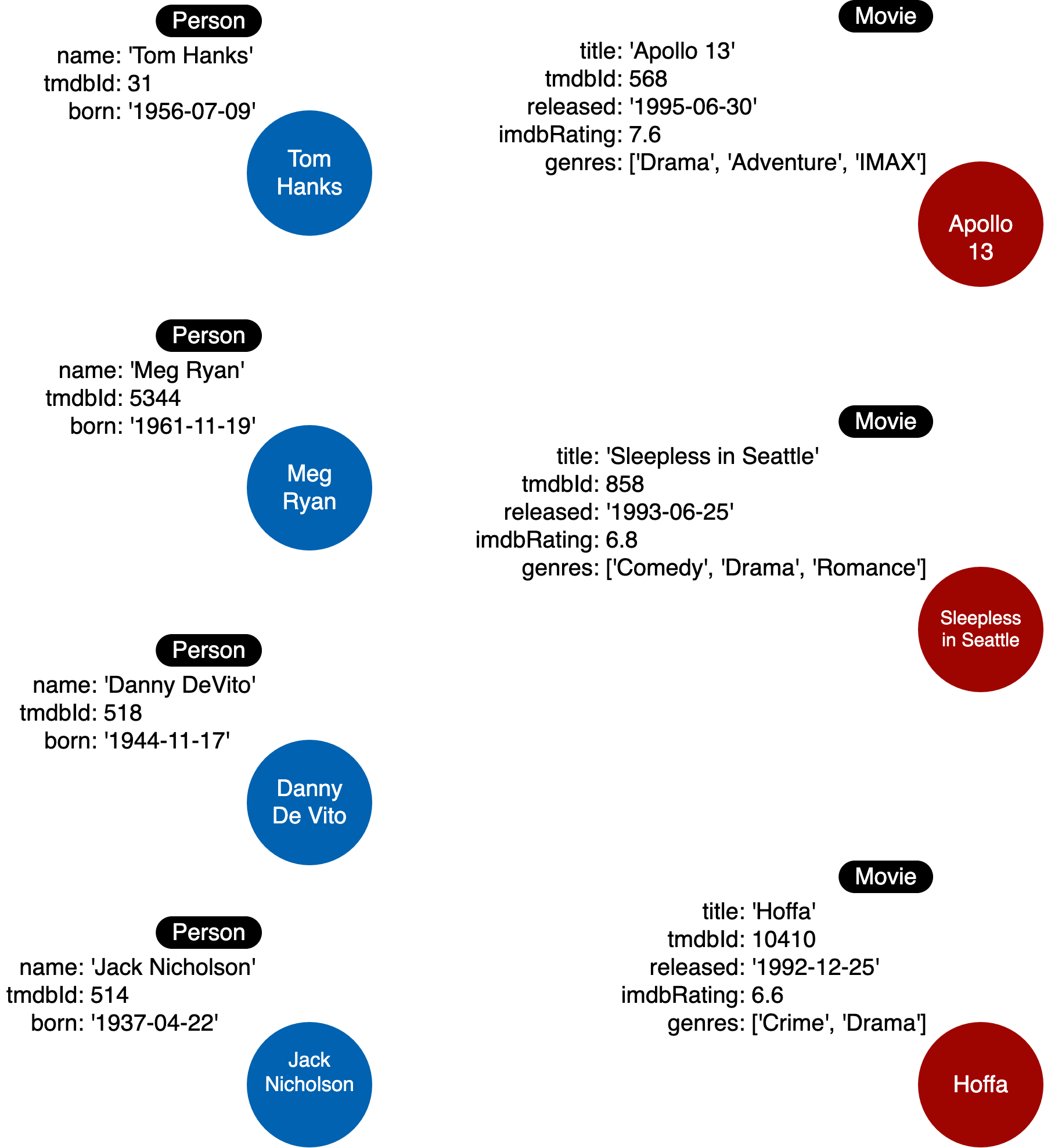
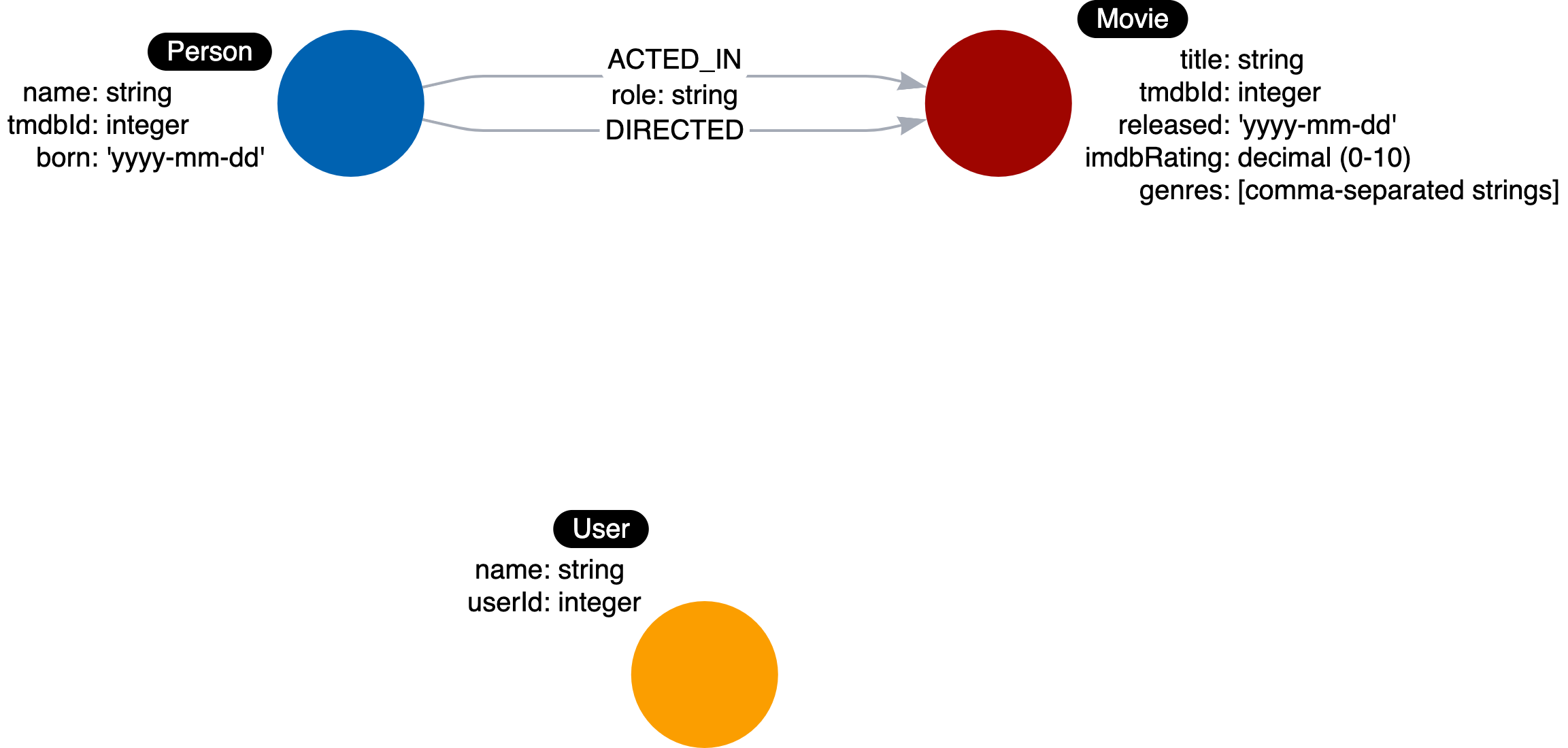
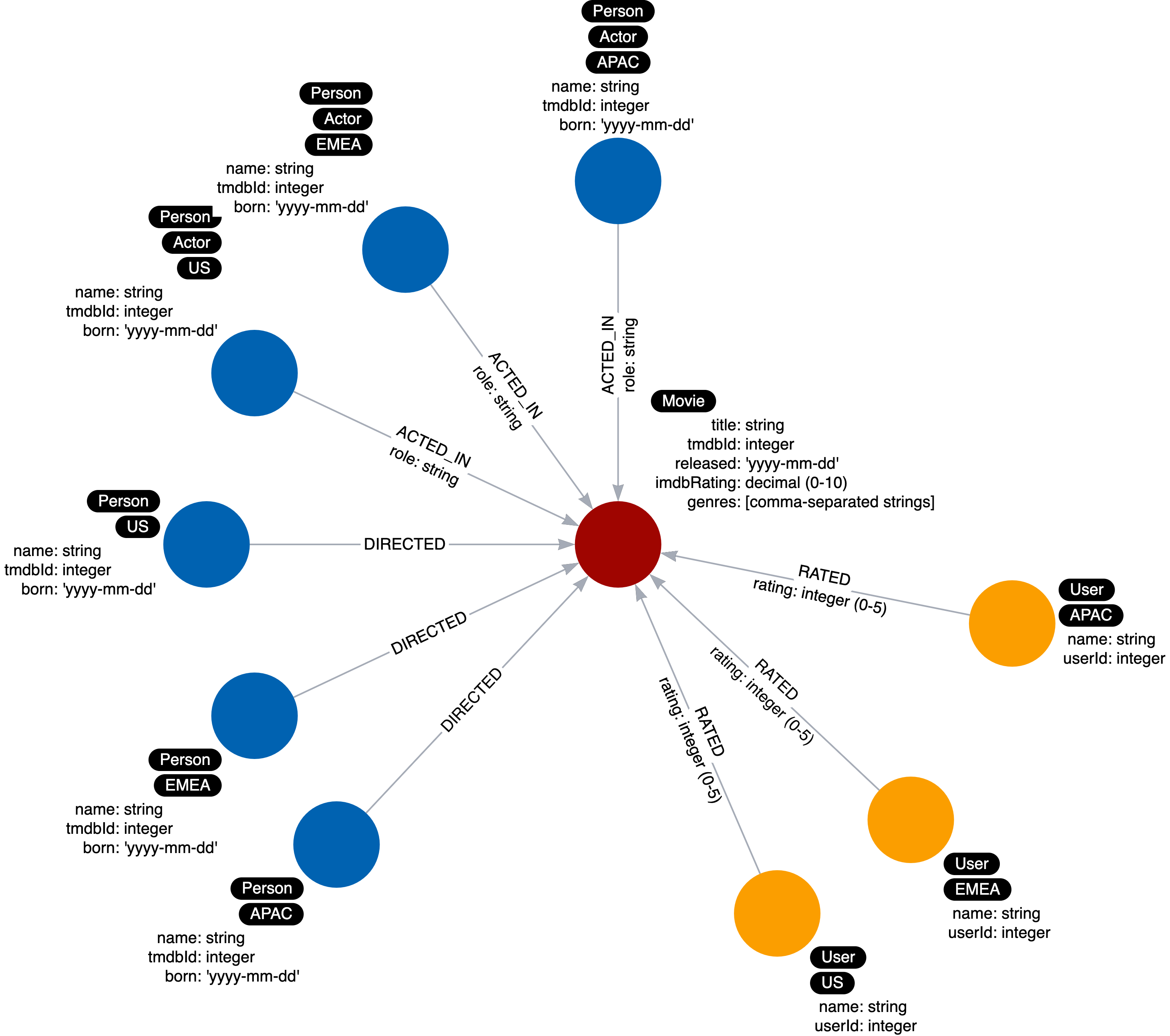
Data model is where you describe labels, relationships, and properties for a graph. An example of data model is shown in the image below.

Syle guideline for data modeling
When creating a data model, it is important to define the labels, relationships, and properties. Here are a style guide recommendation to follow when data modeling in Neo4j:
- A label is a single identifier that begins with a capital letter and can be CamelCase.
- Examples: Person, Company, GitHubRepo
- A relationship type is a single identifier that is in all capital letters with the underscore character.
- Examples: FOLLOWS, MARRIED_TO
- A property key for a node or a relationship is a single identifier that begins with a lower-case letter and can be camelCase.
- Examples: deptId, firstName
Note: Property key names need not be unique. For example, a Person node and a Movie node, each can have the property key of tmdbId.
Instance Model
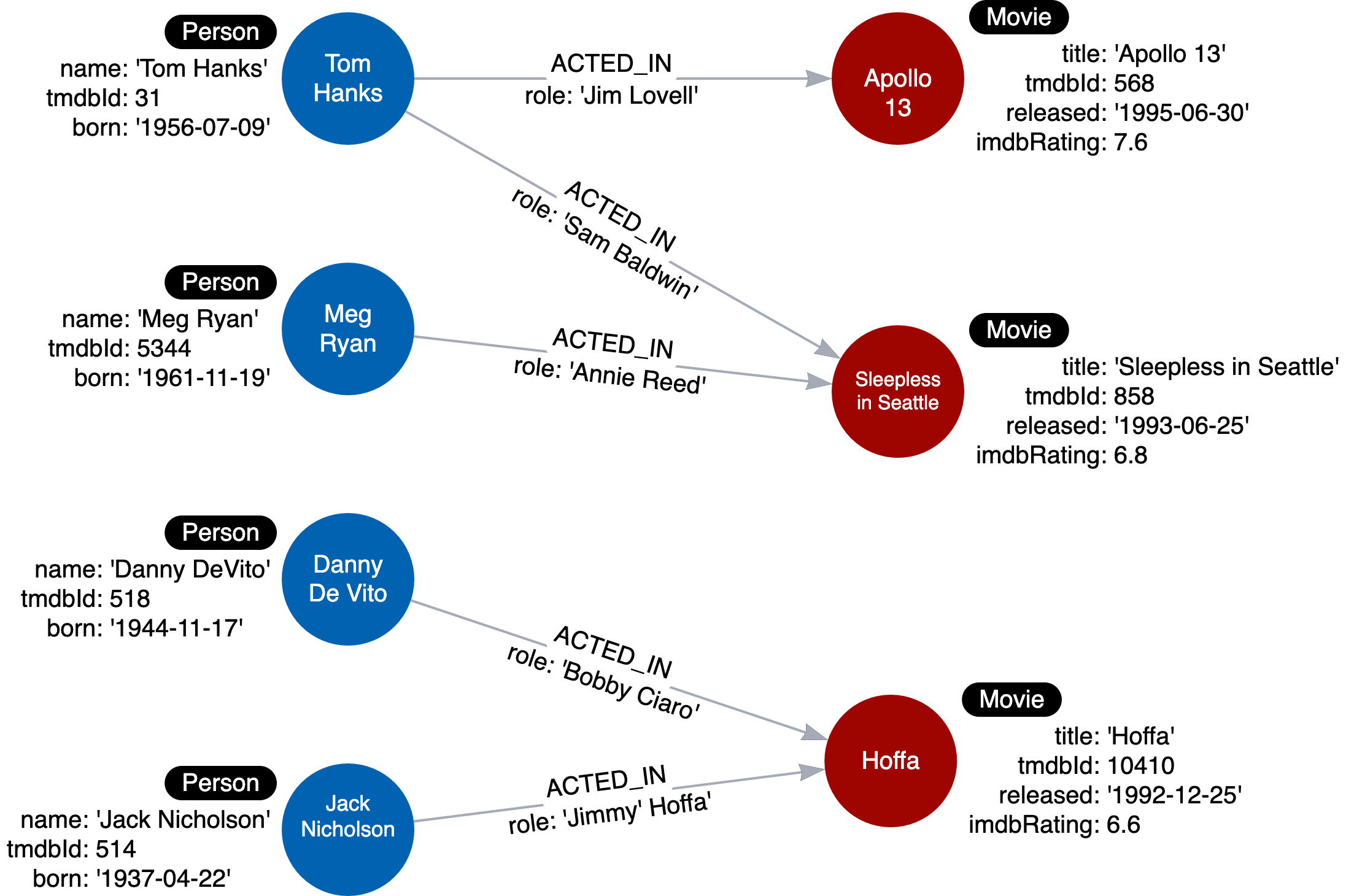
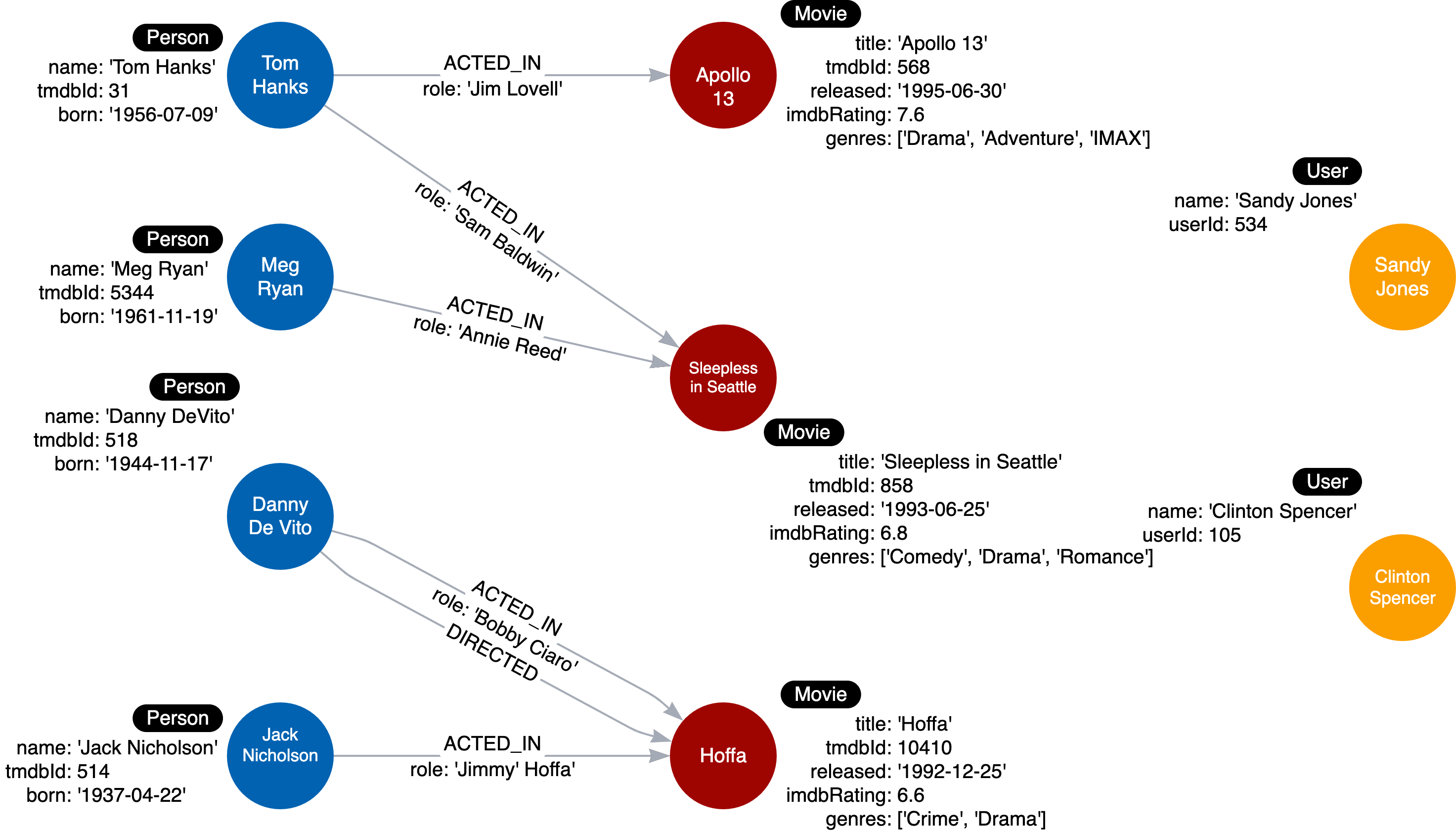
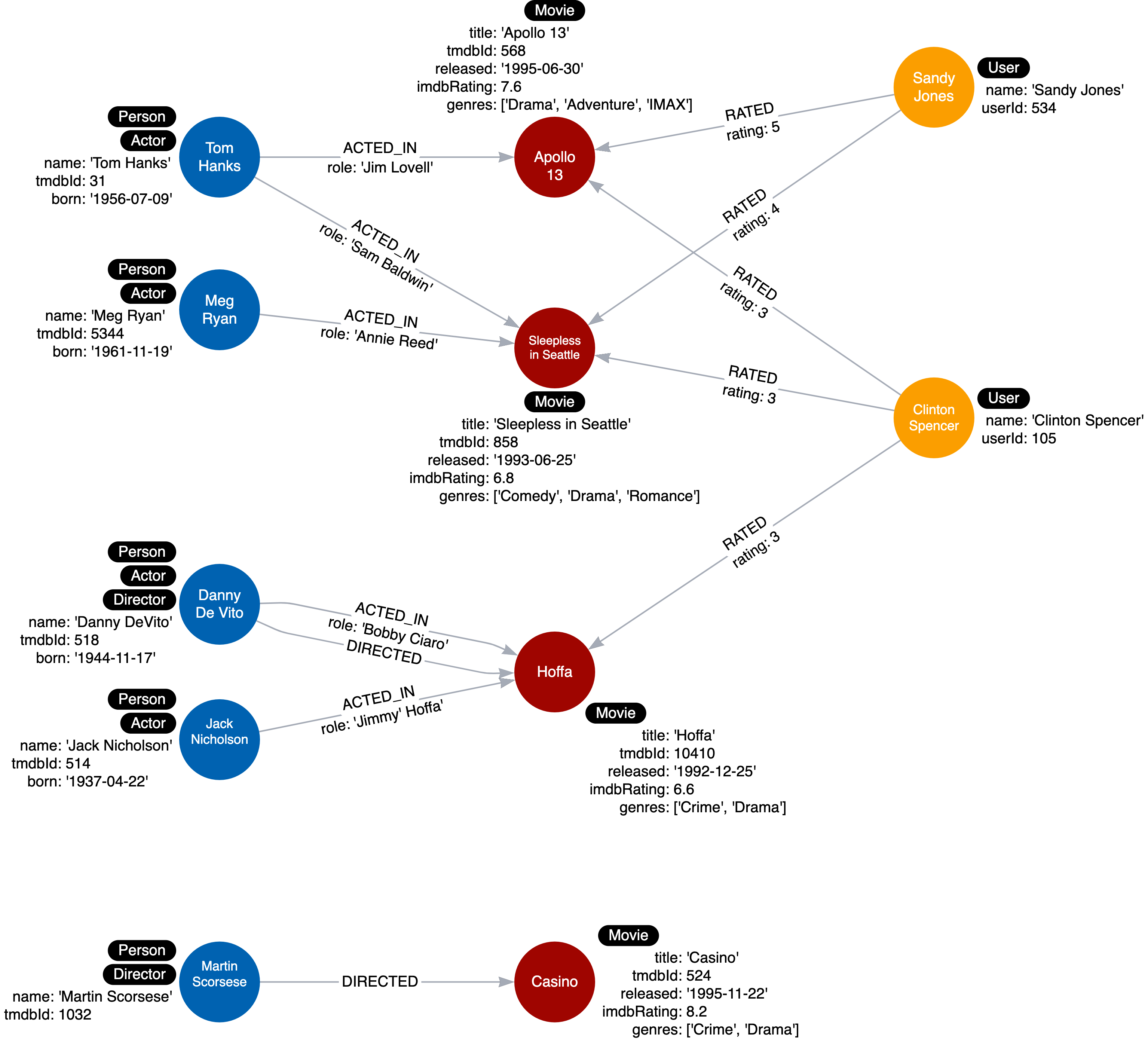
In the instance model, you test your data model using sample/dummy data against your use case. The image below shows an example of an instance model.
Graph Data Modeling Step by Step
Note: use arrows.app to easily build graph data models.
Modeling Nodes
Defining Labels
In a graph, labels are entities in the graph, usually nouns.
In the movie domain, here are some questions/use cases to define the node labels:
- What people acted in a movie?
- What person directed a movie?
- What movies did a person act in?
From the questions above, the node labels are defined as follows:

Node Properties
Node properties are used to:
- Uniquely identify a node.
- Answer specific details of the use cases for the application.
- Return data.
For example, in a Cypher query, properties are used to:
- Anchor (where to begin the query).
MATCH (p:Person {name: 'Tom Hanks'})-[:ACTED_IN]-(m:Movie) RETURN m - Traverse the graph (navigation).
MATCH (p:Person)-[:ACTED_IN]-(m:Movie {title: 'Apollo 13'})-[:RATED]-(u:User) RETURN p,u - Return data from the query.
MATCH (p:Person {name: 'Tom Hanks'})-[:ACTED_IN]-(m:Movie) RETURN m.title, m.released
Defining Node Properties
Similar to how node labels were defined, defining node properties are also done by writing down the questions/use case. However, in this step abstarcting the steps to answer the question are required. Example:
- What people acted in a movie?
- Retrieve a movie by its title.
- Return the names of the actors.
- What person directed a movie?
- Retrieve a movie by its title.
- Return the name of the director.
- What movies did a person act in?
- Retrieve a person by their name.
- Return the titles of the movies.
- Who was the youngest person to act in a movie?
- Retrieve a movie by its title.
- Evaluate the ages of the actors.
- Return the name of the actor.
- What is the highest rated movie in a particular year according to imDB?
- Retrieve all movies released in a particular year.
- Evaluate the imDB ratings.
- Return the movie title.
- What drama movies did an actor act in?
- Retrieve the actor by name.
- Evaluate the genres for the movies the actor acted in.
- Return the movie titles.
From the abstraction above, the following data model is created:

Thus far, our instance model looks like this:
Modeling Nodes (continued)
With the current instance model, we were able to answer several questions/use cases. But, what about this question How many users rated a movie?.
This simply begs the question, “Is all node labels represented?”. Refering back to when we were abstarcting our use cases answers, we only defined node labels for Movie and Person (actor) but didn’t define a node label for imDB users. Thus, we need to update the model to include User as a node label.
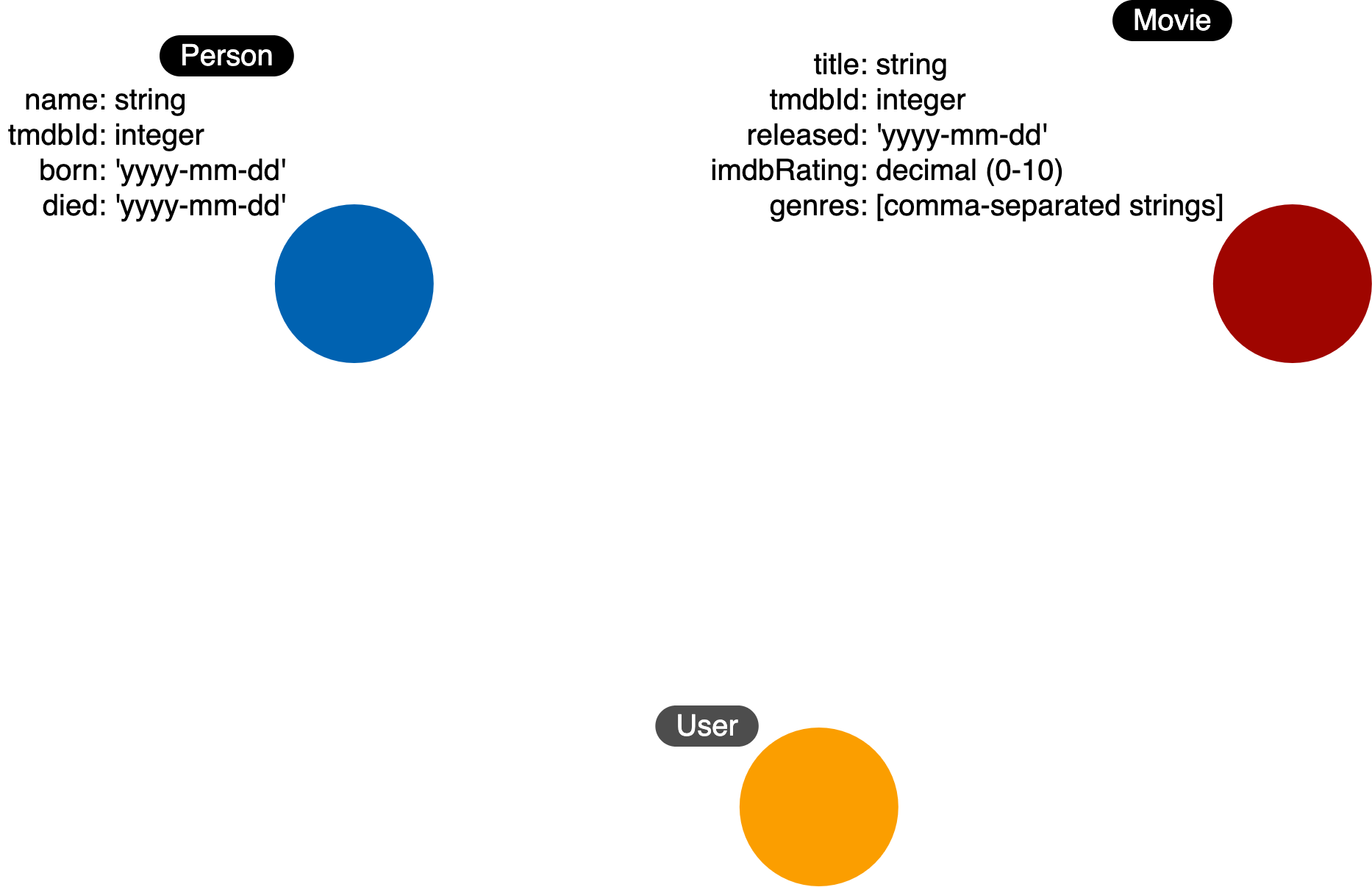
The update above also updated our instance model such as:
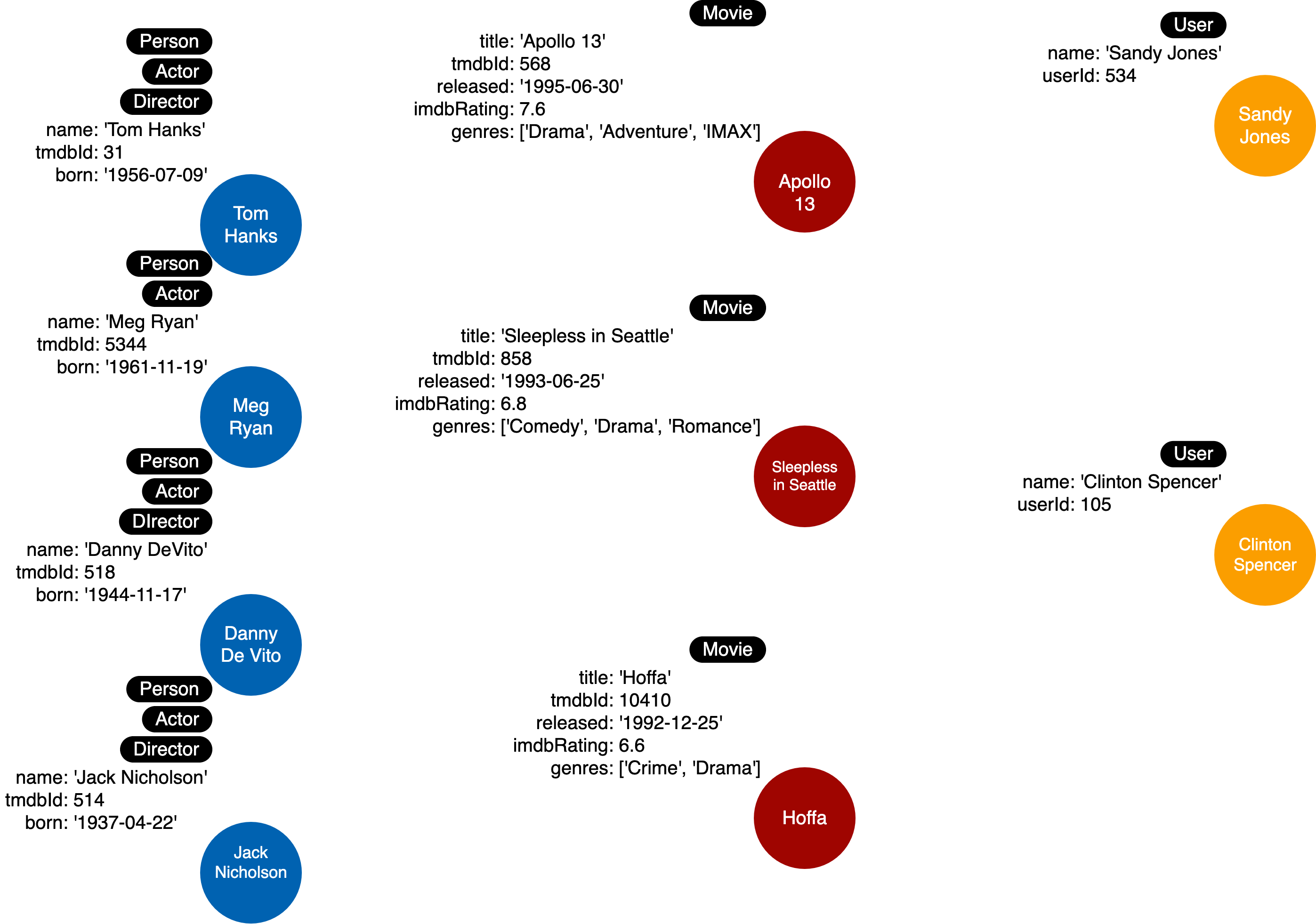
Modeling Relationships
Relationships are connections between entities
Connections are the verbs in your use cases:
- What people acted in a movie?
- What person directed a movie?
- What movies did a person act in?
Given these questions/use cases, we name the relationships:
- ACTED_IN
- DIRECTED

Defining Relationship Properties
To enrich the relationship between two nodes, we can add properties to the relationship. The steps in defining a relationship property is the same as defining node properties.
Lets say you have this question:
- What role did a person play in a movie?
Steps to answer that question in graph will look like this:
- Retrieve the name of the person.
- Follow the ACTED_IN relationships to movies.
- Filter the movie by its title.
- Return the role from the ACTED_IN relationship between the two nodes.
Up to this point, the data model should be updated as follows:
The update above also updated our instance model such as:
Adding More Relationships
Lets say you want to answer this question, What users gave a movie a rating of 5? . How would you answer it?
- Retrieve movie by it’s title.
- Follow the RATED relationships from users to movie.
- Filter RATED relationship by it’s rating property.
- Return the user’s name.
The abstraction above gives us an idea to add RATED relationship from User node to Movie node with property rating which has value an integer between 0 and 5.
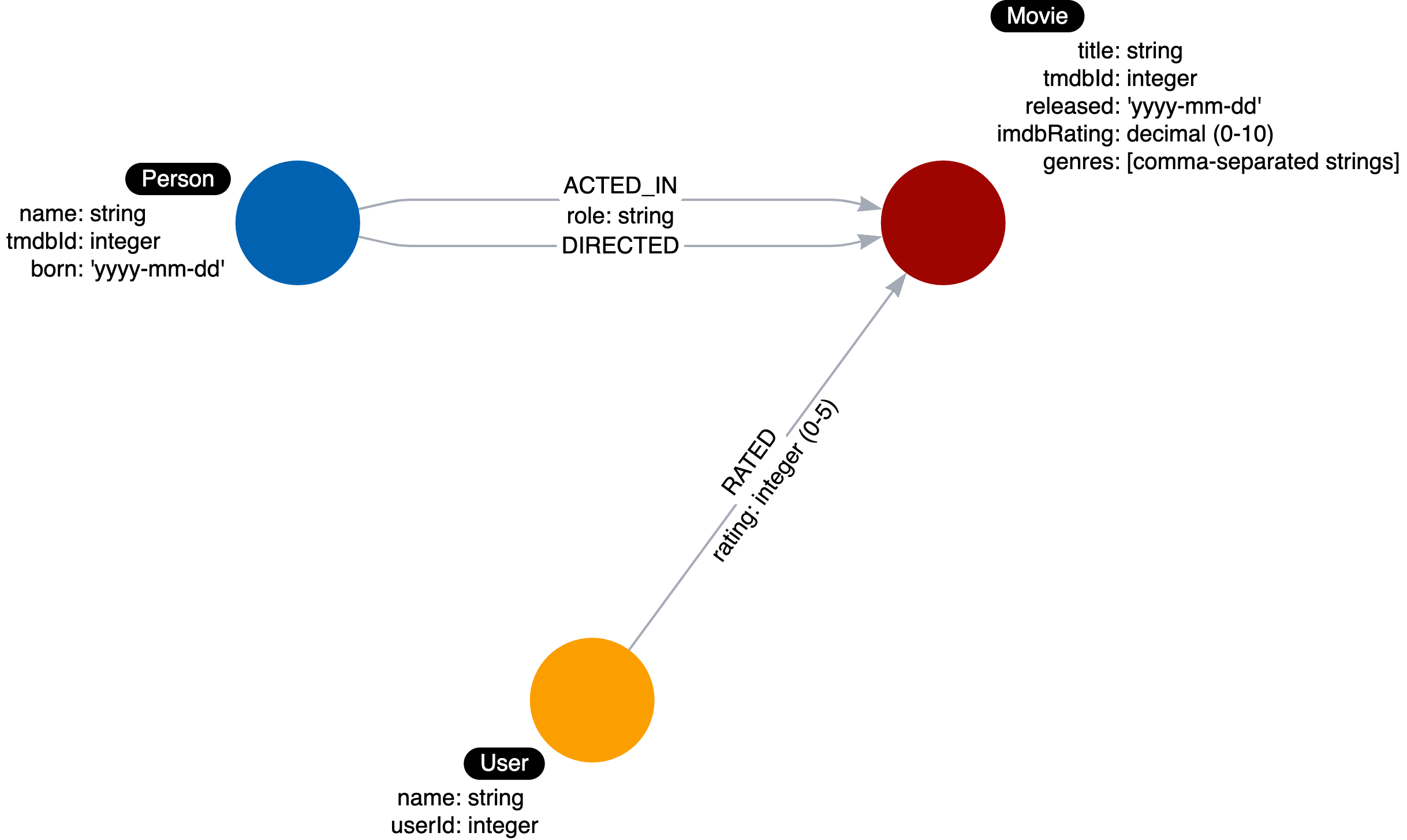
The update above also updated our instance model such as:

Testing Your Data Model
Thus far, we’ve tried answering our use cases using abstarction. At this point you should try testing them using cypher queries.
For example, if you want to answer this question, What people acted in a movie?. Your cypher query will look like this:
MATCH (p:Person)-[:ACTED_IN]-(m:Movie)
WHERE m.title = 'Sleepless in Seattle'
RETURN p.name AS ActorYou may also want to define your expected answer (["Tom Hanks", "Meg Ryan"] for the test case above).
Besides of use case testing, You also may want to test your data model with it’s scalability. This is where you test your cypher queries performance against a growing graph with millions of nodes or relationships.
Model Refactoring
Why Refactor?
- The graph as modeled does not answer all of the use cases.
- A new use case has come up that you must account for in your data model.
- The Cypher for the use cases does not perform optimally, especially when the graph scales
Refactoring Procedure
- Design the new data model.
- Write Cypher code to transform the existing graph to implement the new data model.
- Retest all use cases, possibly with updated Cypher code.
Labels in A Graph
Labels at runtime
Node labels serve as an anchor point for a query. By specifying a label, we are specifying a subset of one or more nodes with which to start a query. Using a label helps to reduce the amount of data that is retrieved/scanned.
For example:
MATCH (n) RETURN nreturns all nodes in the graph.MATCH (n:Person) RETURN nreturns all Person nodes in the graph.
Your goal in modeling should be to reduce the size of the graph that is touched by a query.
You can check the number of nodes scanned by profiling your cypher query using the PROFILE clause before your cypher query. Alternatively, you can use EXPLAIN clause if you want to see cypher’s query plan. A key difference between PROFILE and EXPLAIN is EXPLAIN doesn’t execute the query, thus giving you an estimate of the execution plan, while PROFILE executes the query and gives you the exact number of scans performed/resource usage to execute your query.
Adding Labels
Notice that in the data model we’ve made so far, we’ve been using the Person label quite often. It’s okay to do so, but there are options to reduce node scanning for this data model because a Person in our model actually represents an actor and director. Execute the following query to add Actor label to Persons who acted in movies:
MATCH (p:Person)
WHERE exists ((p)-[:ACTED_IN]-())
SET p:ActorThis gives us the following instance model:
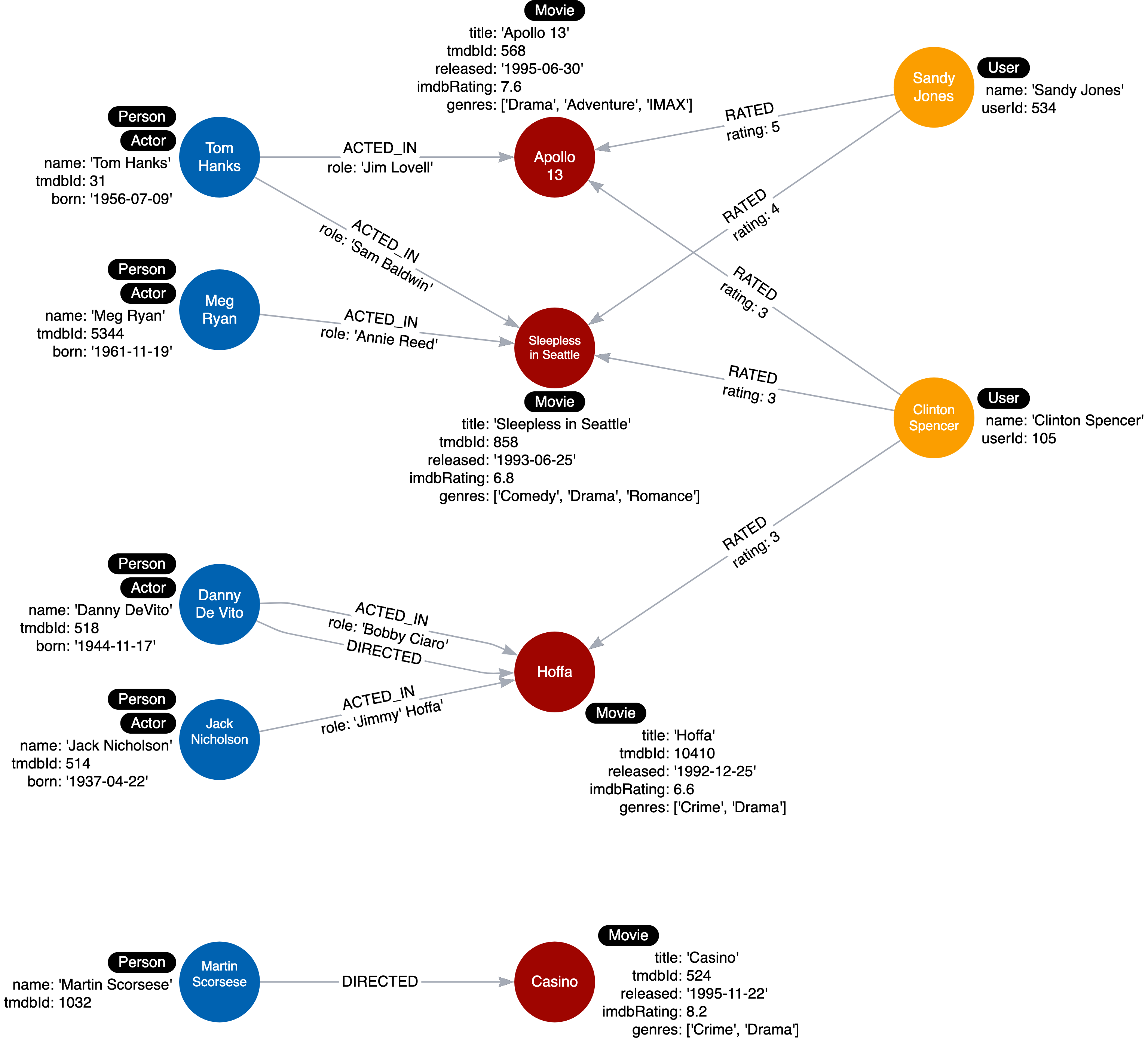
Note: Neo4j’s best practice is that a node can have 4 labels maximum.
Retesting The Data Model
Now that we’ve added a new label Actor, we need to retest all use cases that were affected by the data model changes. For example, in order to answer this use case, What people acted in a movie?, we used the following cypher query:
MATCH (p:Person)-[:ACTED_IN]-(m:Movie)
WHERE m.title = 'Sleepless in Seattle'
RETURN p.name AS ActorNow that we have the actor label, we can reduce the number of node scans by using the actor label instead of using the person label. The cypher query becomes:
MATCH (p:Actor)-[:ACTED_IN]-(m:Movie)
WHERE m.title = 'Sleepless in Seattle'
RETURN p.name AS ActorBy doing so we successfully reduce the number of node scans from 5 to 4. This can be proven using the PROFILE clause.
Initial cypher query profiling:
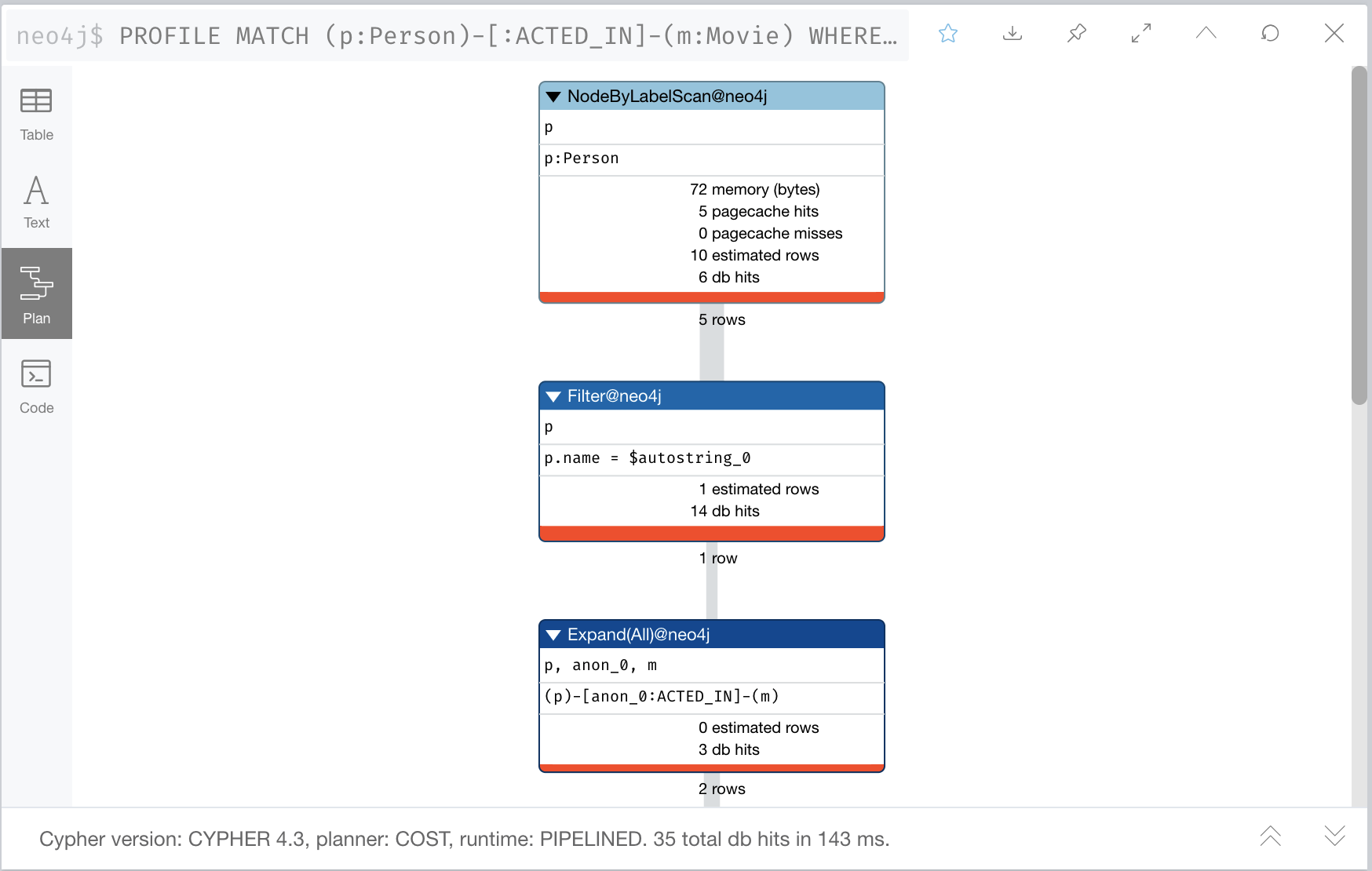
Refactored cypher query profiling:

Adding More Labels
Notice that the Person label also has the DIRECTED relationship, lets add a director label to people who directed a movie by executing the following cypher query:
MATCH (p:Person) WHERE exists ((p)-[:DIRECTED]-()) SET p:DirectorThis updates our instance model to be like this:
Node Labels to Avoid
When data modeling, there are 2 kinds of labels that you should avoid.
- Semantically orthogonal labels
Semantically orthogonal labels means that each label has nothing to do with each other. Suppose adding regions to our data model doesn’t help in our use case, don’t add them to the nodes containing other labels with different meanings.
- Labels representing class hierarchies
Suppose you have hierarchies like this:
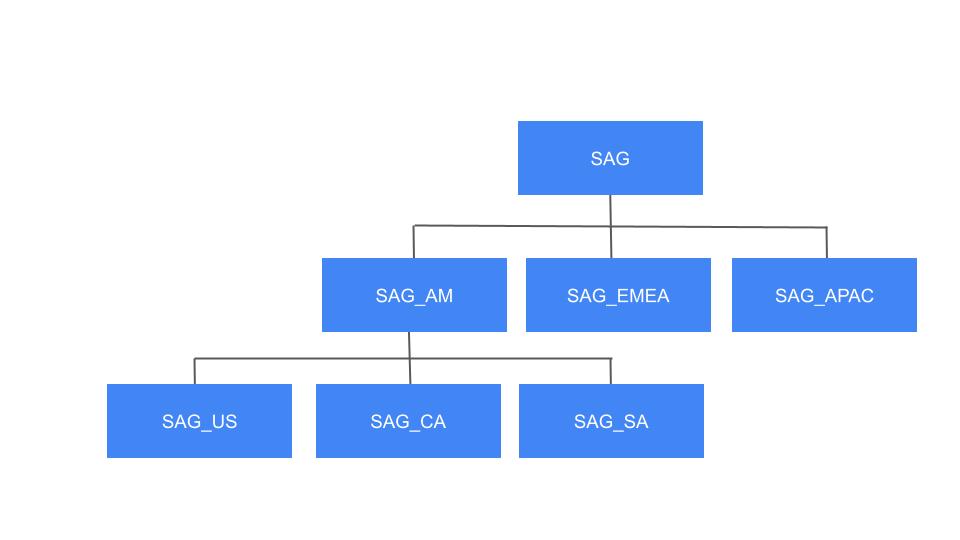 You want to model a person’s hierarchies, don’t do this:
You want to model a person’s hierarchies, don’t do this:
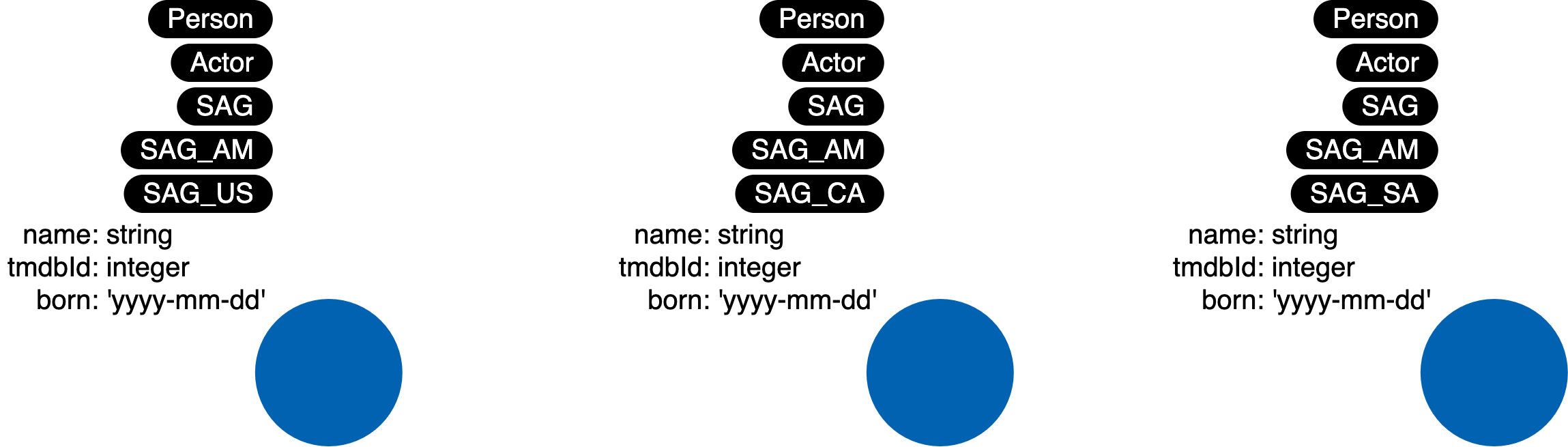 Do this instead:
Do this instead:
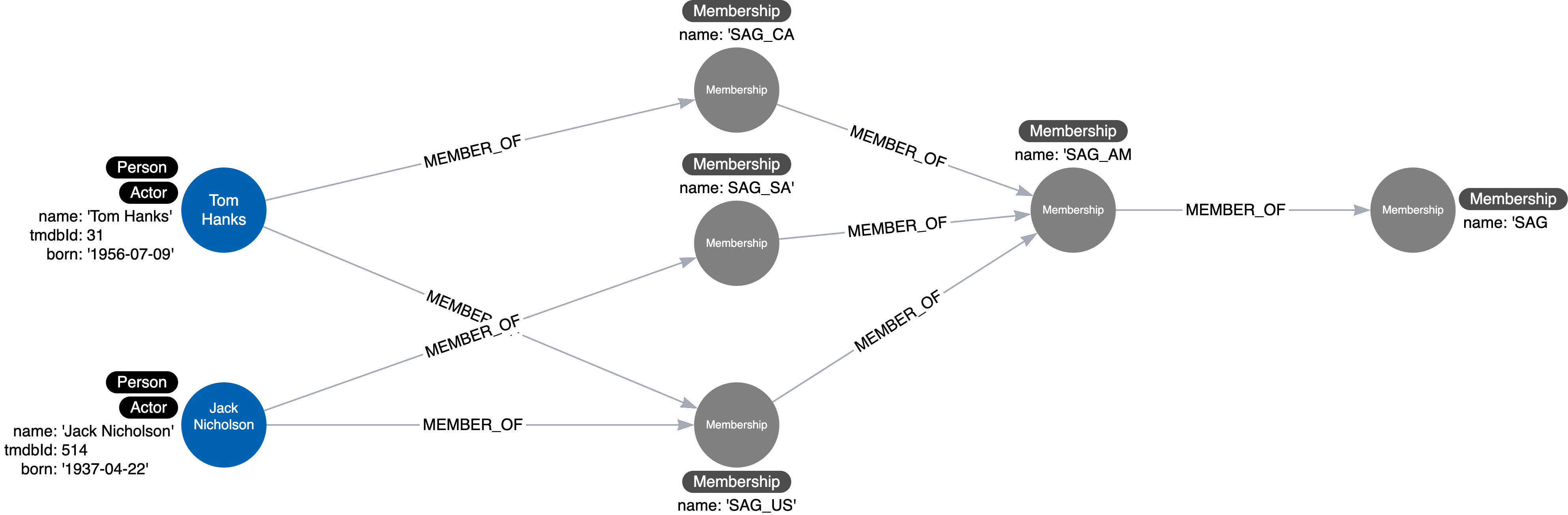
Avoiding Duplication
In order to improve query performance, some databases require a database denormalization. However, this is not the case for graph database. The power of graph database is in the traversal, thus deduplicating becomes a crucial part of improving database performance in graph database.
Lets say in tha movie database, you need to handle this use case, What movies are available in a particular language?.
Our current instance model didn’t account for this. You can quickly handle this by adding a language property to the movies like this:
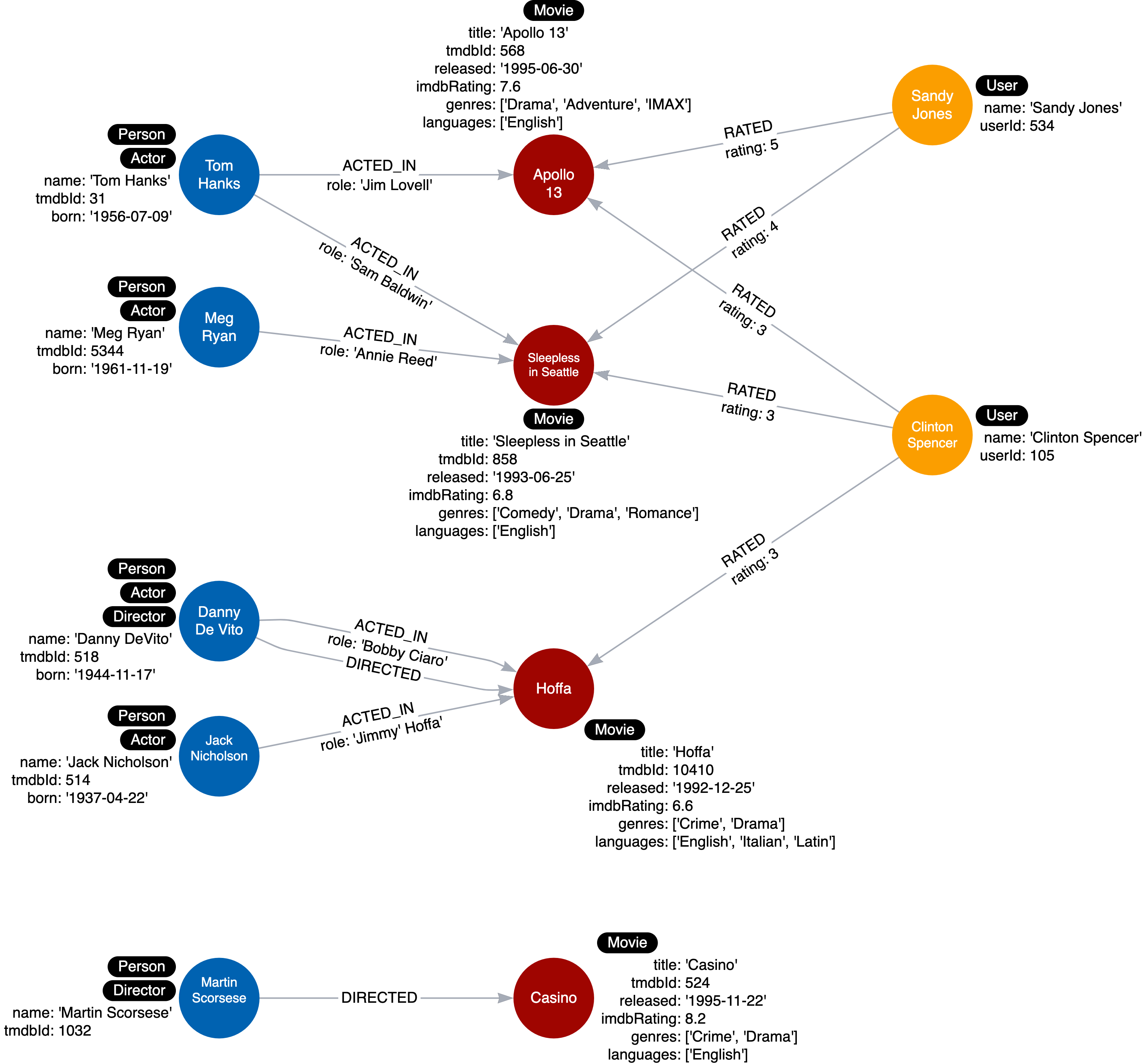
Looking at the instance model, you will notice that all language properties has the language English in it. This is duplicate data and for a scaled database, would represent a lot of duplication.
Refactoring Duplicate Data
Using the instance model above, if we want to answer the question What movies are available in a particular language?, our cypher query will look like this:
MATCH (m:Movie)
WHERE 'Italian' IN m.languages
RETURN m.titleThis cypher query is problematic because:
- The name of the language is duplicated in many Movie nodes.
- In order to perform the query, all Movie nodes must be retrieved.
A better way, will be to represent the languages as nodes, such as:

By doing so, the cypher query becomes:
MATCH (l:Language {name:'Italian'})<-[:IN_LANGUAGE]-(m:Movie)
RETURN m.titleWith this query, Neo4j only needs to look at the language once and can directly traverse to the movies in that language.
Updating the data model to this model is done by utilizing the WITH and UNWIND clause.
WITHstores selected variables temporarily and removes unselected variables.UNWINDseperates an array to rows.
The whole cypher query to achive this is as follows:
MATCH (m:Movie)
UNWIND m.languages AS language
WITH language, collect(m) AS movies
MERGE (l:Language {name:language})
WITH l, movies
UNWIND movies AS m
WITH l,m
MERGE (m)-[:IN_LANGUAGE]->(l);
MATCH (m:Movie)
SET m.languages = nullDeduplicating genres property
If you paid attention to the genres property, you will notice the same thing as language property is happening. The following is are queries to refactor the graph data model and answer the question What drama movies did an actor act in?
- Current cypher query for
What drama movies did an actor act in?use caseMATCH (p:Actor)-[:ACTED_IN]-(m:Movie) WHERE p.name = 'Tom Hanks' AND 'Drama' IN m.genres RETURN m.title AS Movie - Refactoring query
MATCH (m:Movie) UNWIND m.genres AS genres WITH genres, collect(m) AS movies MERGE (g:Genre {name:genres}) WITH g, movies UNWIND movies AS m WITH g,m MERGE (m)-[:IN_GENRE]->(g); MATCH (m:Movie) SET m.genres = null - Updated cypher query for use case
MATCH (g:Genre {name:'Drama'})<-[:IN_GENRE]-(m:Movie) RETURN m.title
Now your instace model looks like this:

Other sources of duplicate data
Duplicated data in a graph is not always inside a list. Take a look at the instance model below.

Looking at the instance model, you will notce that both Nodes with label ProductionCompany has an address which are located in “CA”. This can be modeled such as:

Using this instance model, you can easily search for production companies by traversing through the graph instead of looking into the properties of each node seperately (This follows the index-free adjacency principle).
Specific Relationships
Lets look at a new use case for the movie database, What movies did an actor act in for a particular year?
For this use case, executing the folowing cypher query will suffice:
MATCH (p:Actor)-[:ACTED_IN]-(m:Movie)
WHERE p.name = 'Tom Hanks' AND
m.released STARTS WITH '1995'
RETURN m.title AS MovieBut what if “Tom Hanks” acted in 1000 movies? The query above will still work but it needs to scan through all 1000 movies to search for movies that are released in 1995. This is where specific relationship type comes in. We can move the movie release year to the relationship such as:
- ACTED_IN_1992
- ACTED_IN_1993
- ACTED_IN_1995
- DIRECTED_1992
- DIRECTED_1995
This will result in an instance model which looks like this:
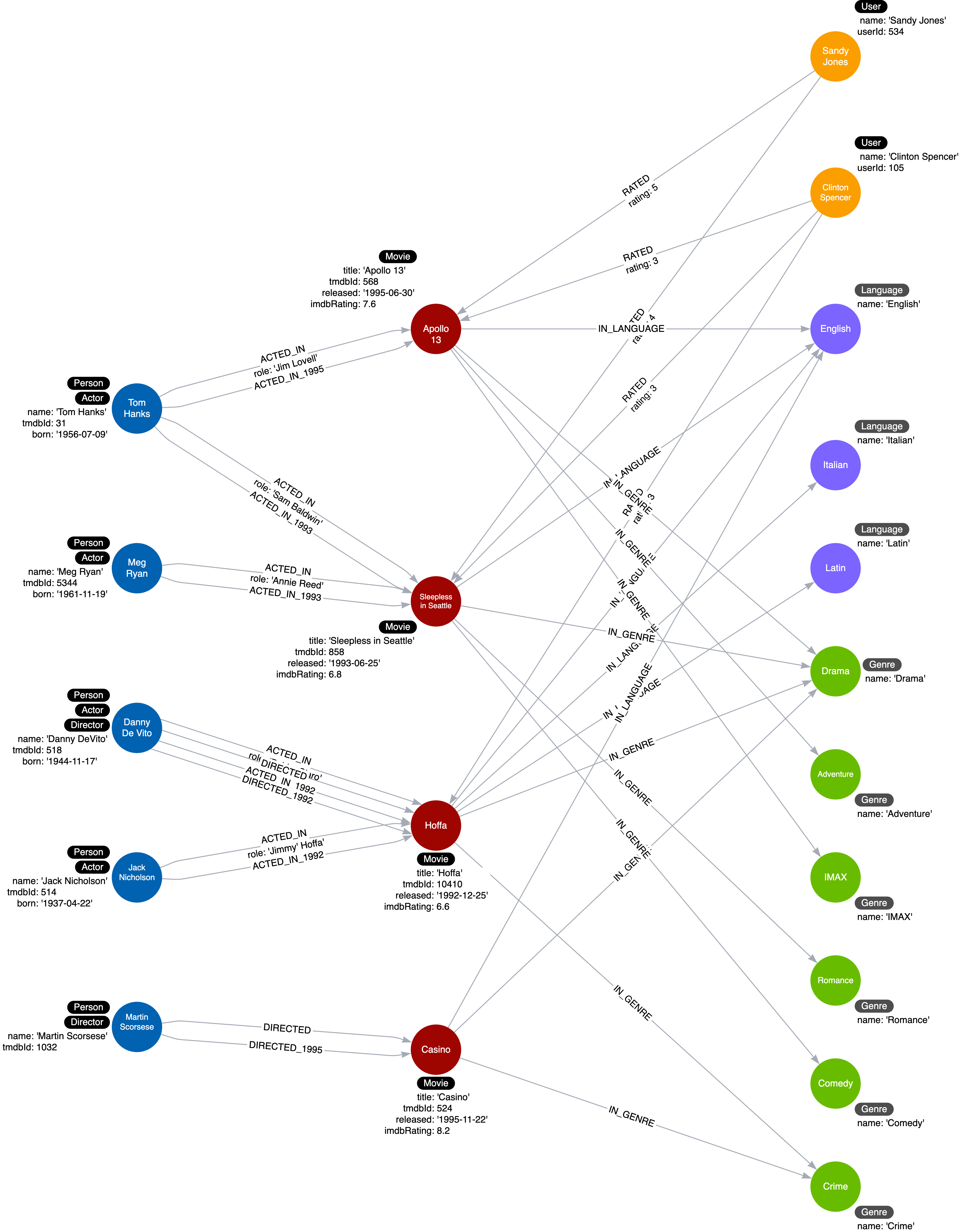
Having mentioned before, the power of a graph database is in it’s relationships traversal. With specific relationships, in case “Tom Hanks” acted in 1000 movies the graph database doesn’t need to scan through all 1000 movies to find movies where “Tom Hanks” acted in 1995. Instead Neo4j can utilize the relationships and the query will finish.
MATCH (p:Actor)-[:ACTED_IN_1995]-(m:Movie)
WHERE p.name = 'Tom Hanks'
RETURN m.title AS MovieIn order to update our current data model, we can utilize the APOC library.
MATCH (n:Actor)-[r:ACTED_IN]->(m:Movie)
CALL apoc.merge.relationship(n,
'ACTED_IN_' + left(m.released,4),
{},
{},
m ,
{}) YIELD rel
RETURN COUNT(*) AS `Number of relationships merged`Model refactoring for (n:Director)-[:DIRECTED]->(m:Movie) is done in a similar way.
MATCH (n:Director)-[r:DIRECTED]->(m:Movie)
CALL apoc.merge.relationship(n,
'DIRECTED_' + left(m.released,4),
{},
{},
m ,
{}) YIELD rel
RETURN COUNT(*) AS `Number of relationships merged`The current instance model looks like this:
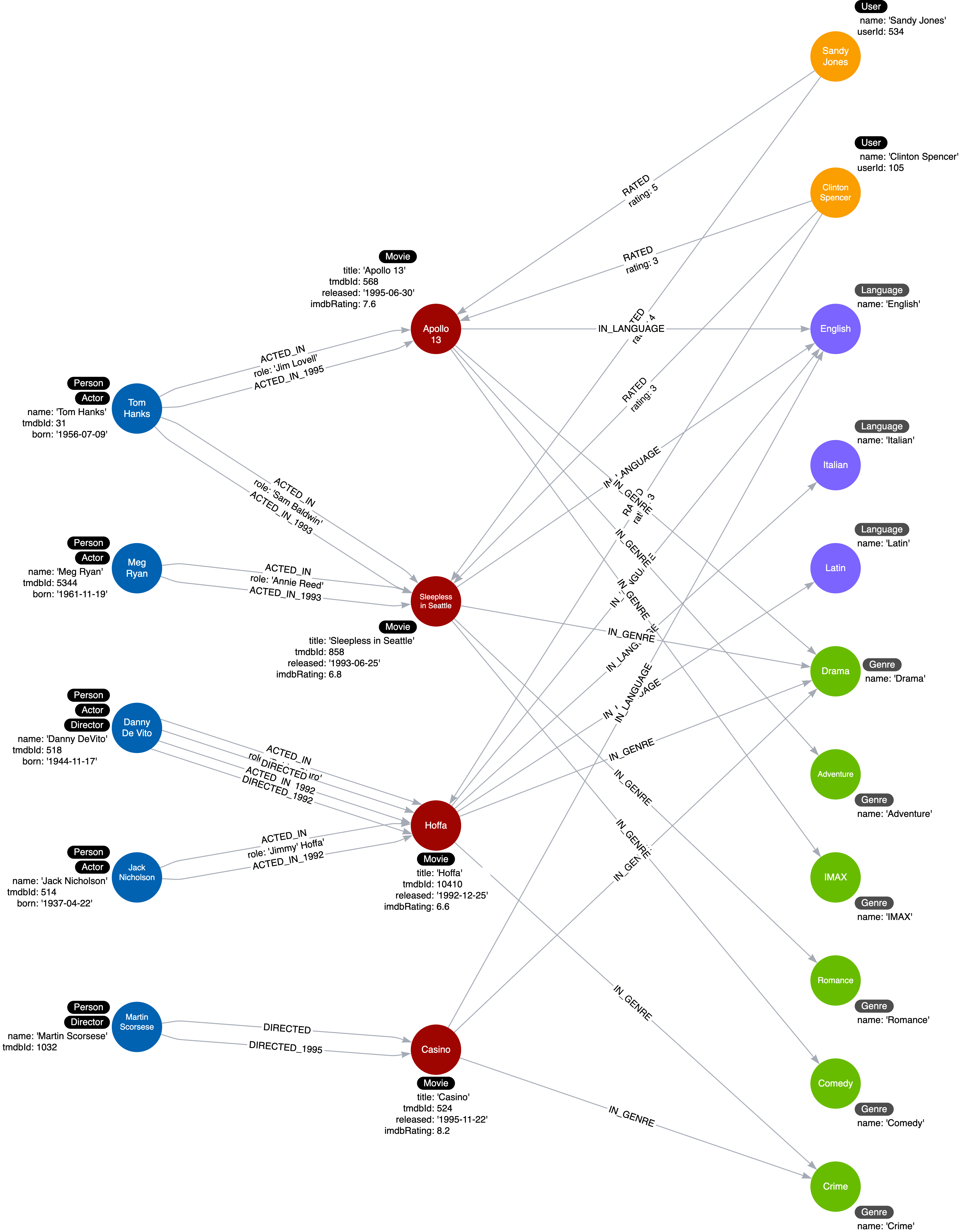
Similarly, specific relationships can also be applied to (u:User)-[r:Rated]->(m:Movie).
MATCH (u:User)-[r:RATED]->(m:Movie)
CALL apoc.merge.relationship(u,
'RATED_' + toString(r.rating),
{},
{},
m ,
{}) YIELD rel
RETURN COUNT(*) AS `Number of relationships merged`Intermediate Nodes
Sometimes in a data model, you can put too many information in relationship property or you are actually trying to share an entity with other entities but haven’t defined the shared entity yet in the data model.
In general, you create intermediate nodes when you need to:
- Connect more than two nodes in a single context.
- Hyperedges (n-ary relationships)
- Relate something to a relationship.
- Share data in the graph between entities.
Example: Need for intermediate nodes
Imagine you’re working on a people analytics platform and you are given the following instance model:

In the intance model, you will be noticed that the relationship WORKS_AT is actually a hyperedge (an edge consisting of many edges). A better way to model this graph is by replacing the hyperedge with an intermediate node, such as it becomes:
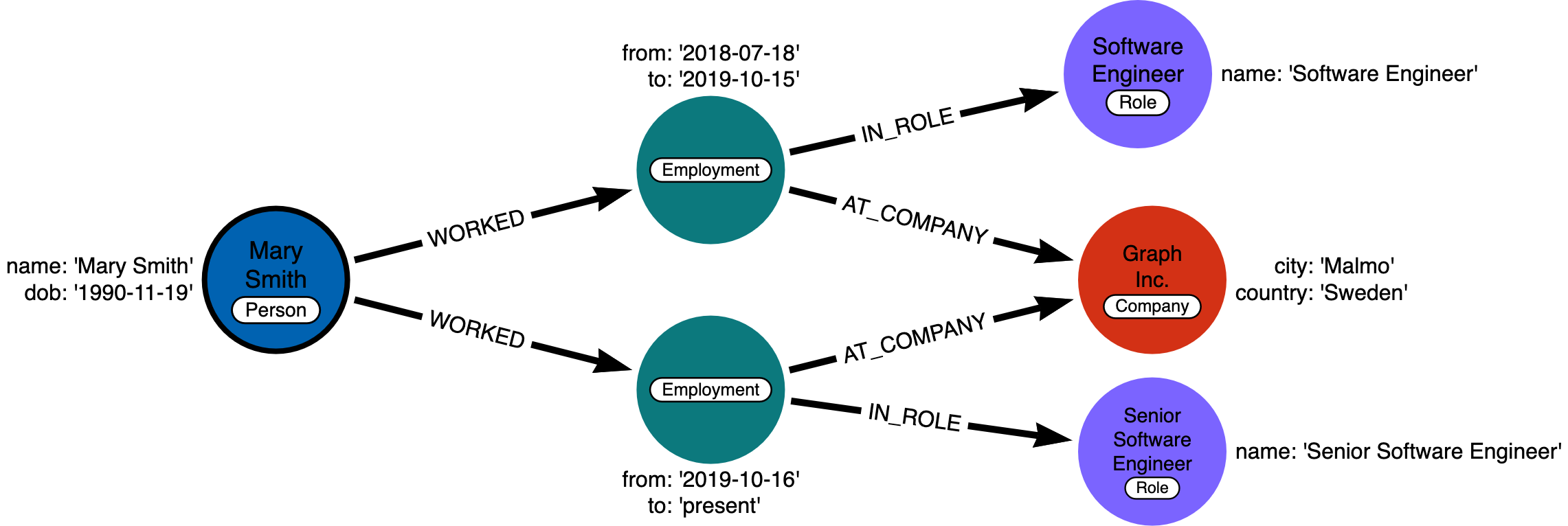
This way, Person nodes can have a shared Role or Company, and allow us to very easily trace either the full details of a single person’s career, or the overlap between different individuals.
Example: Intermediate nodes for sharing data
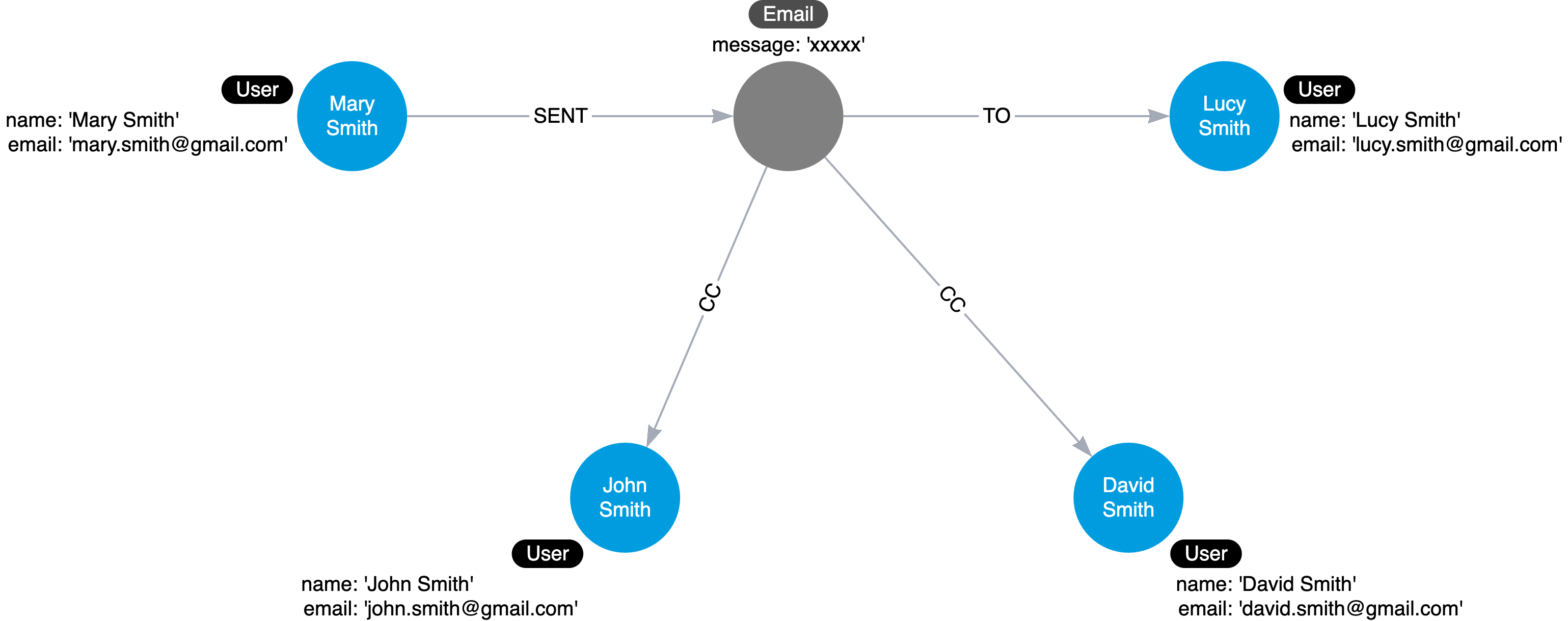
Another case where intermediate nodes may be necessary is the use case of sharing an entity. The instance model below depicts a graph model of sending email.

Notice that the message property is duplicated 3 times. This can be better modeled using the following instace model:
Example: Movie Database Actors Role
Lets revisit, our movie database instance model:
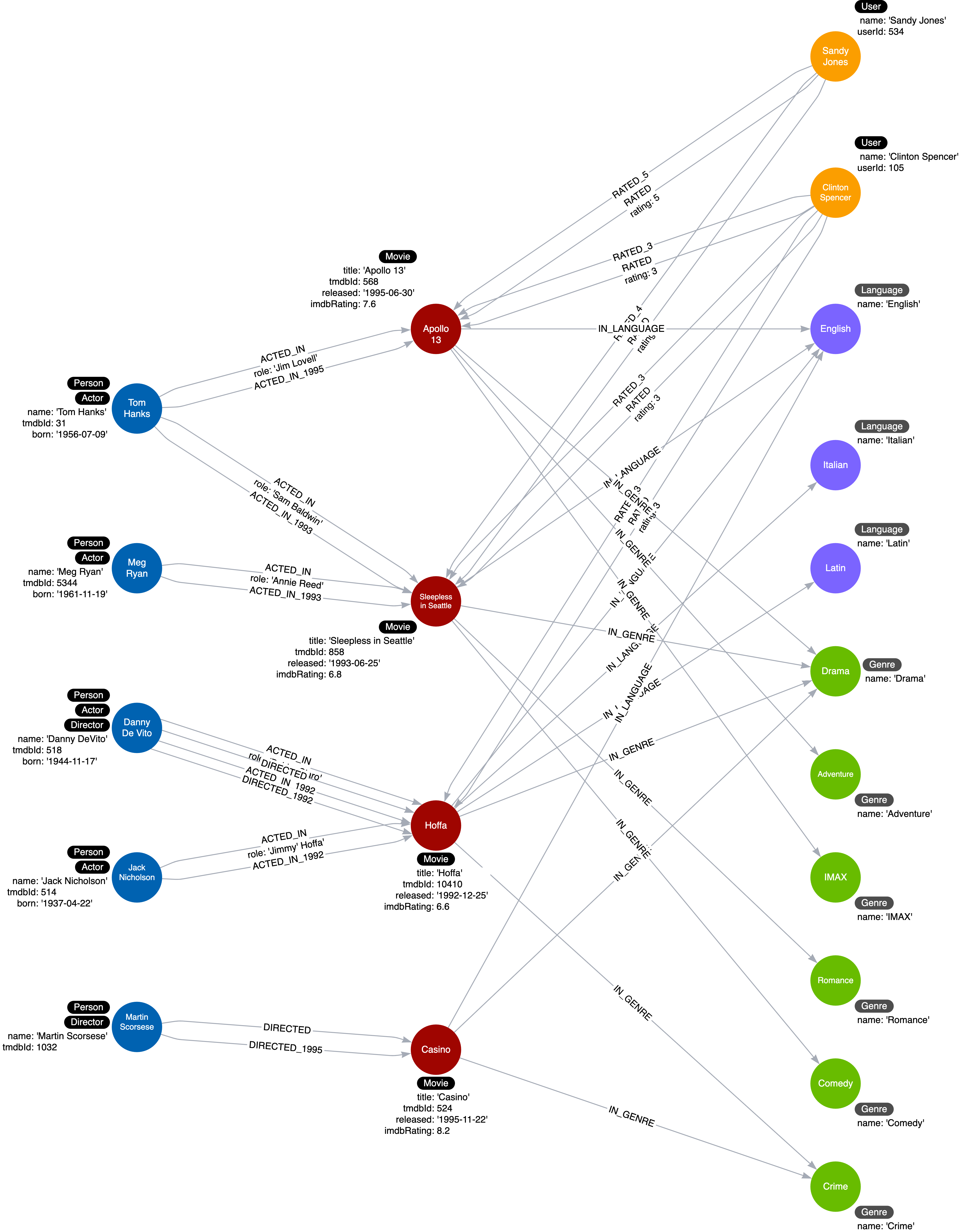
In the graph model above, the role that an actor plays in a movie is stored as a property in the ACTED_IN relationship. In this model, 1 actor is only playing a single role. However, there are some instances where an actor is required to play multiple roles in a movie. Thus, storing the role as a node label makes sense. The updated instance model will look like this:
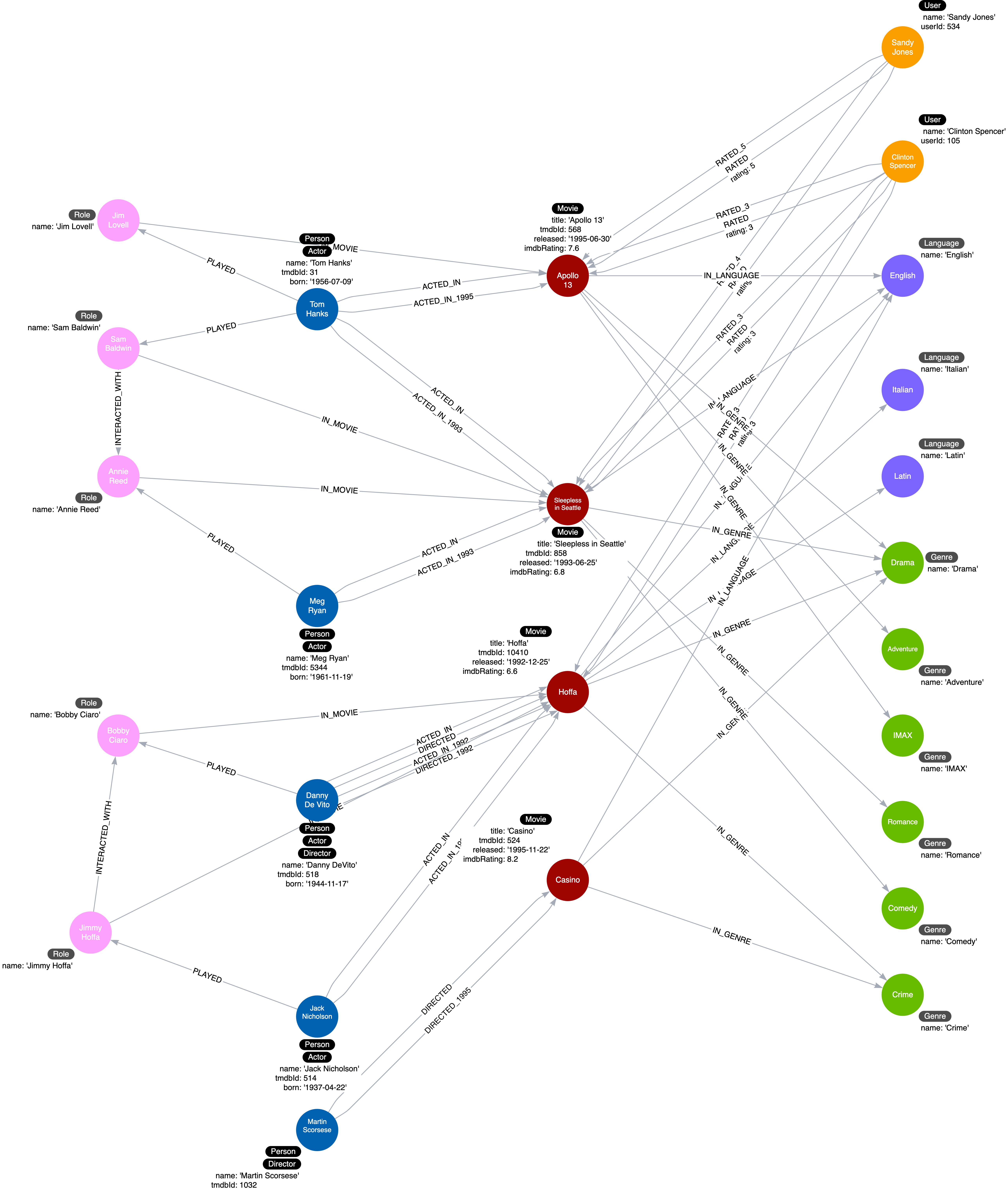
In order to update the current instance model (without the INTERACTED_WITH relationships between roles), you can run the cypher query below.
MATCH (a:Actor)-[r:ACTED_IN]-(m:Movie)
MERGE (a)-[:PLAYED]->(role:Role{name:r.role})-[:IN_MOVIE]->(m)
SET r.role = nullAdditional Note
In order to check your graph data model’s schema, you can execute the following Cypher query:
CALL db.schema.visualization()or
CALL apoc.meta.graph